Brain Netflix: Scaling Data to Reconstruct Videos from Brain Signals
Accepted at ECCV 2024
Click to view our poster
Abstract
The field of brain-to-stimuli reconstruction has seen significant progress in the last few years, but techniques continue to be subject-specific and are usually tested on a single dataset. In this work, we present a novel technique to reconstruct videos from functional Magnetic Resonance Imaging (fMRI) signals designed for performance across datasets and across human participants. Our pipeline accurately generates 2 and 3-second video clips from brain activity coming from distinct participants and different datasets by leveraging multi-dataset and multi-subject training. This helps us regress key latent and conditioning vectors for pretrained text-to-video and video-to-video models to reconstruct accurate videos that match the original stimuli observed by the participant. Key to our pipeline is the introduction of a 3-stage approach that first aligns fMRI signals to semantic embeddings, then regresses important vectors, and finally generates videos with those estimations. Our method demonstrates state-of-the-art reconstruction capabilities verified by qualitative and quantitative analyses, including crowd-sourced human evaluation. We showcase performance improvements across two datasets, as well as in multi-subject setups. Our ablation studies shed light on how different alignment strategies and data scaling decisions impact reconstruction performance, and we hint at a future for zero-shot reconstruction by analyzing how performance evolves as more subject data is leveraged.
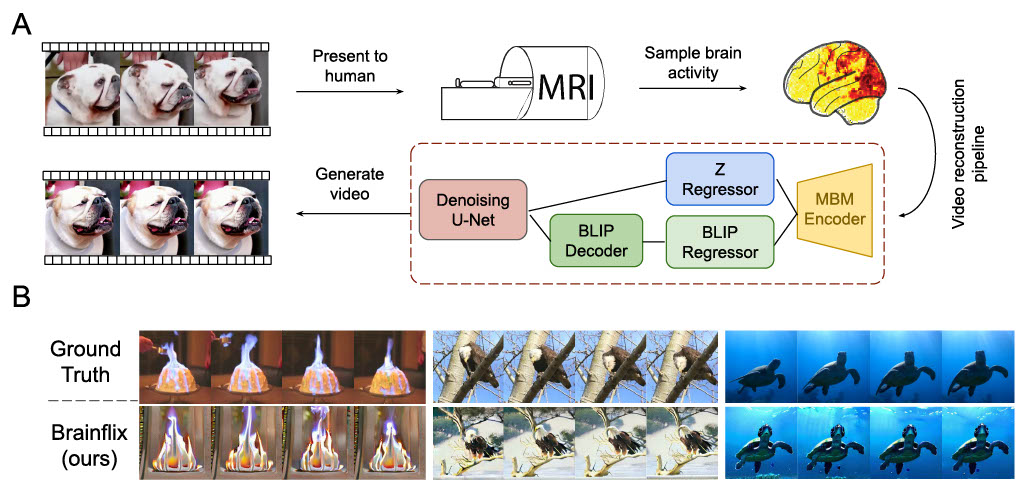
Reconstruction Framework
Our reconstruction framework is composed of three stages: (1) Alignment between fMRI and videos (CLIP embeddings) using Masked Brain Modeling (MBM), (2) Regression of visual and semantic features into latent embeddings, and (3) Reconstruction of videos from fMRI data using stage 1's MBM encoder, stage 2's latent embeddings, and a video generation model. We achieve a large scale of data by compiling four large fMRI datasets: Human Connectome Project resting state [1], BOLD Moments Dataset [2], Human Actions Dataset [3], and CC2017 [4]. We use Zeroscope V2 [5] as our video generation model as we find it achieves the best reconstruction results (see our ICML workshop paper for a comparison of models).
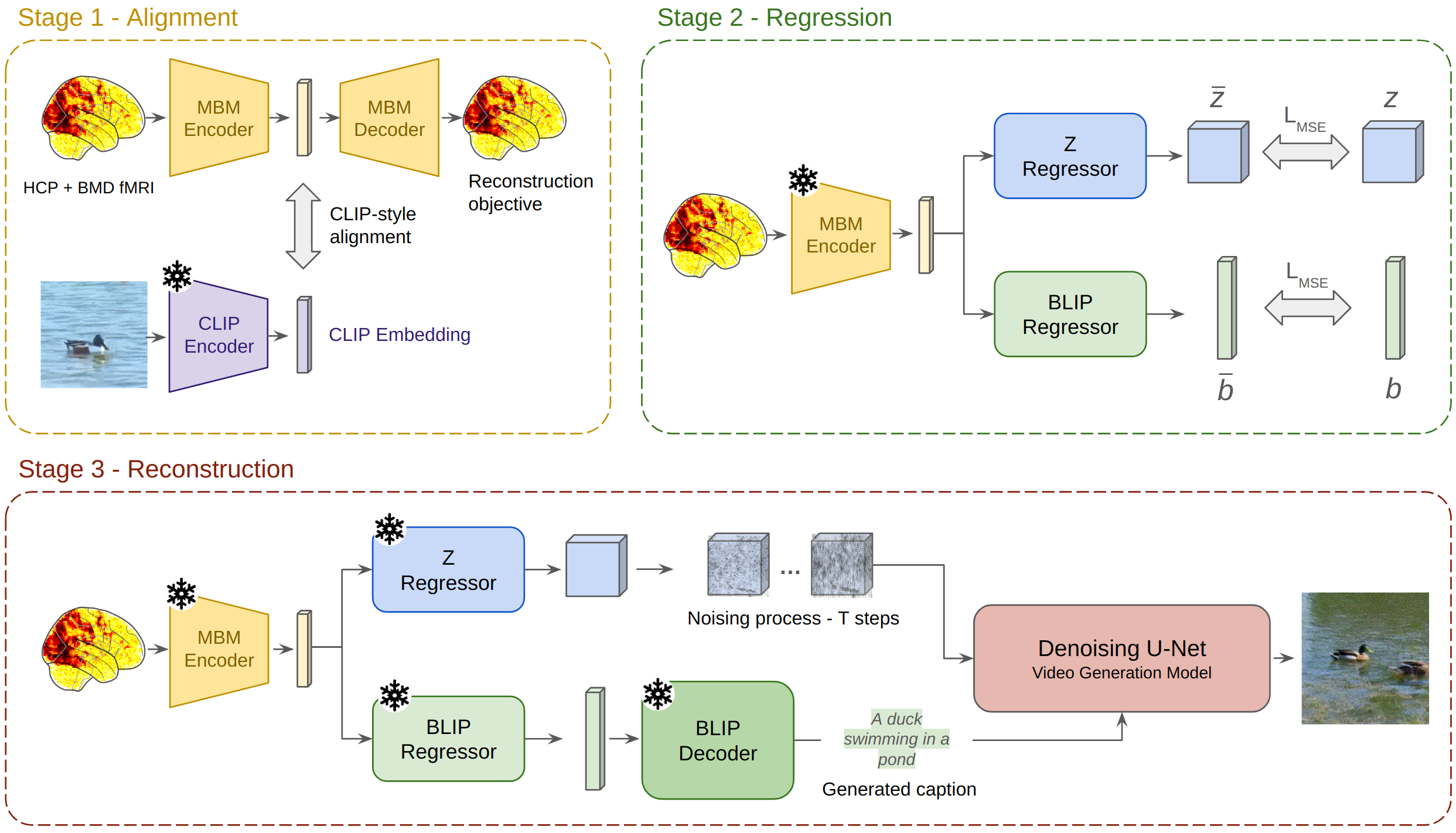
Reconstruction Results
We find that our video reconstructions outperform other leading methodologies in both qualitative (human judgement) and quantitative metrics.

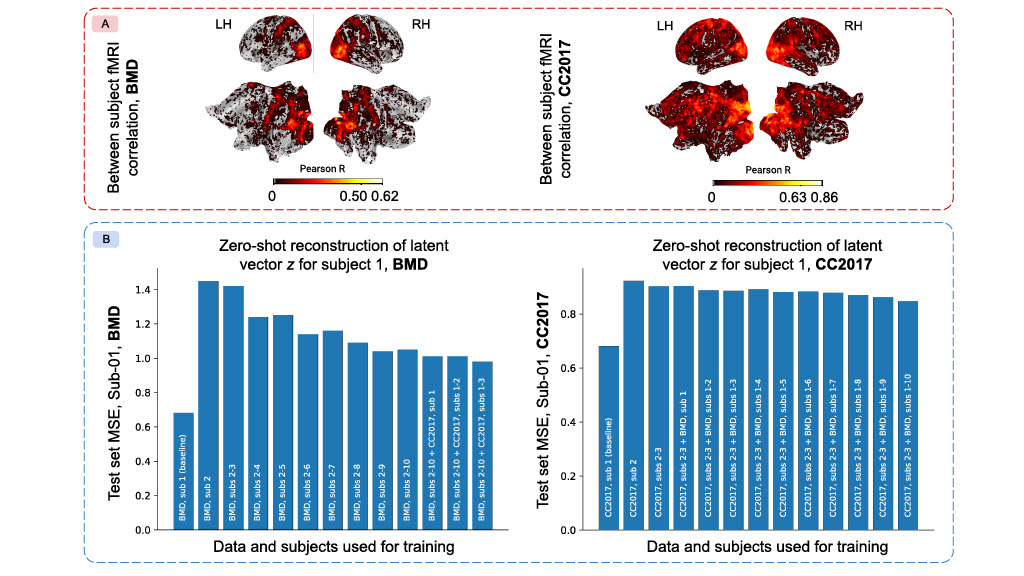
Zero Shot Reconstructions
We examine how well we can reconstruct videos from subject 1's fMRI data by training our pipeline on only fMRI data from other subjects. We first show between-subject pairwise correlations in the BMD and CC2017 datasets to highlight shared brain responses throughout visual cortex and beyond (panel A). In panel B, we see that adding fMRI data from additional subjects improves reconstruction performance on the left-out subject, but, at the scale achieved in this paper, the reconstructions do not yet meet the baseline.
More Reconstruction Examples and Failure Cases
We show more examples of successful reconstructions on the BOLD Moments Dataset and CC2017 dataset (panels A and D). We also observe failure cases (panels B, C, E, F, G) where reconstructions contain high frequency noise, dominance of semantic descriptions over low-level features, and superposition of shapes over an otherwise faithful reconstruction.

Acknowledgements
This research was funded by the Multidisciplinary University Research Initiative (MURI) award by the Army Research Office (grant No. W911NF-23-1-0277) to A.O; the MIT EECS MathWorks Fellowship to B.L.; the MIT EECS MathWorks Fellowship to C.F.
References
- Van Essen, D. C., Smith, S. M., Barch, D. M., Behrens, T. E., Yacoub, E., Ugurbil, K., & Wu-Minn HCP Consortium. (2013). The WU-Minn human connectome project: an overview. Neuroimage, 80, 62-79.
- Lahner, B., Dwivedi, K., Iamshchinina, P., Graumann, M., Lascelles, A., Roig, G., ... & Cichy, R. (2024). Modeling short visual events through the BOLD moments video fMRI dataset and metadata. Nature Communications, 15(1), 6241.
- Zhou, M., Gong, Z., Dai, Y., Wen, Y., Liu, Y., & Zhen, Z. (2023). A large-scale fMRI dataset for human action recognition. Scientific Data, 10(1), 415.
- Wen, H., Shi, J., Zhang, Y., Lu, K. H., Cao, J., & Liu, Z. (2018). Neural encoding and decoding with deep learning for dynamic natural vision. Cerebral cortex, 28(12), 4136-4160.
- Hysts. Zeroscope v2. https://huggingface.co/ spaces/hysts/zeroscope-v2, 2024. Accessed: 2024-06-05.